자료구조(data structure)는 효율적으로 데이터를 관리하고 수정, 삭제, 탐색, 저장할 수 있는 데이터 집합을 말합니다.
대표적으로 스택, 큐, 힙, 리스트 등이 있습니다.
복잡도
시간 복잡도, 공간 복잡도
빅오 표기법(Big-O)
시간 복잡도란 "문제를 해결하는 데 걸리는 시간과 입력의 함수 관계"를 가리킵니다. 알고리즘 로직이 "얼마나 오랜 시간"이 걸리는지를 함수형식으로 표현해 주는 것을 빅오 표기법이라고 하고, 예시를 들어 입력 크기 n에 대해서 알고리즘을 해결하는 데 걸리는 시간이 O(n^3)이라고 하면, 다음과 같은 코드를 생각할 수 있습니다.
int ans = 0;
for(int i=1;i<=n-2;i++)
{
for(int j=i+1;j<=n-1;j++)
{
for(int k=j+1;k<=n;k++)
{
if(check[i][j] || check[j][k] || check[k][i]) continue;
ans+=1;
}
}
}또한, 시간 복잡도가 존재하는 이유는 효율적인 코드로 개선하는데 쓰이는 척도가 되기 때문입니다.

다음과 같이 효율적인 코드를 작성하였을 때, 입력 크기에 따라 걸리는 시간이 n^2, n, logn, 1에 따라서 크게 차이 남을 확인할 수 있습니다. 그래서 프로그래머들은 시간 복잡도를 신경 써서 코드를 작성해야 한다고 생각합니다.
공간복잡도
공간복잡도란, 프로그램을 실행시켰을 때 필요로 하는 자원 공간의 양을 말합니다. 단지 정적 변수에 포함하는 메모리 공간을 의미하는 것도 맞는 사실이지만, 동적 함수(ex: 재귀 함수) 호출로 공간을 필요로 하는 경우도 포함됩니다.
자료구조의 시간 복잡도

선형 자료 구조
선형 자료 구조란 요소가 일렬로 나열되어 있는 자료구조를 의미합니다.
1. 연결 리스트(데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화 시킨 자료구조 (삽입, 삭제 연산 O(1), 탐색 O(n))
- 싱글 연결 리스트 - next 포인터만 가짐
- 이중 연결 리스트 - next 포인터 + prev 포인터
- 원형 이중 연결 리스트 : - 이중 연결 리스트와 동일하지만, 마지막 노드의 next 포인터가 헤드노드를 가리킴
이중 연결 리스트 코드 예시
- push_back() : 뒤에서부터 요소 삽입
- push_front() : 앞에서부터 요소 삽입
- insert() : 중간에 요소 삽입, 매개변수에 해당 인덱스를 가리키는 포인터를 넣어줘야 합니다.
emplace 함수 vs push 함수
기능적으론 동일하지만, emplace 함수는 연산에 필요한 인자를 전달받고, push 함수는 연산에 객체를 전달받는다는 점에서 차이가 있습니다.
아까 설명드렸던 공간 복잡도를 생각해보면, push 함수 대신 emplace 함수를 쓰는 것이 더욱 메모리적으로 효율적입니다. 왜냐하면 push함수는 저희 눈에 보이지는 않지만, 임시 벡터에 객체의 값을 복사하고, 저희가 만든 벡터에 옮기는 과정 담겨있고, emplace함수는 객체 대신 인자를 전달받고, 내부적으로 처리하기 때문입니다. 하지만, 컴파일러 내부적으로 최적화된다는 말도 있어서 어떤 걸 써도 상관없다는 의견도 존재합니다.
2. 배열
배열(array)은 같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터를 모아놓은 집합입니다. 또한 중복을 허용하고, 순서가 있습니다. (탐색 O(1), 삽입 및 삭제 O(n), 연결리스트와 정반대)
정적 배열을 기반으로 한다고 가정했을 때, 탐색이 O(1)이 되고, 랜덤 하게 접근이 가능합니다. 하지만, 삽입과 삭제 연산은 O(N)이므로, 데이터의 추가와 삭제를 많이 하는 것은 연결 리스트, 탐색을 많이 하는 경우에는 배열을 사용하여 효율적으로 자료구조를 사용할 수 있도록 해야 합니다.
3. 벡터
벡터(vector)는 동적으로 요소를 할당할 수 있는 동적 배열입니다. 컴파일 시점에 개수를 모르면 벡터를 써야 하고, 중복을 허용하고 랜덤 접근이 가능하며 탐색과 맨 뒤의 요소를 삭제하거나 삽입하는 데는 O(1)이 걸리며, 맨 뒤나 맨 앞이 아닌 요소를 삭제하고 삽입하는 데 O(n)의 시간이 걸립니다.
- push_back() : 뒤부터 요소를 더하는 함수
- pop_back() : 맨 뒤부터 지우는 함수
- erase() : 특정 요소를 지울 수 있는 함수
- find() : 특정 요소를 찾는 함수
- clear() : 배열 초기화 함수
4. 스택
LIFO의 성질을 가진 자료구조, 재귀적인 함수, 알고리즘에 많이 사용되며 웹 브라우저 방문 기록 등에 쓰입니다. (삽입 및 삭제 O(1), 탐색 O(n))
5. 큐
FIFO의 성질을 가진 자료구조, CPU 작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 행렬, 너비 우선 탐색, 캐시 등에 사용됩니다.
비선형 자료 구조
비선형 자료 구조란 일렬로 나열하지 않고, 자료 순서나 관계가 복잡한 구조를 말합니다. 예시로는 트리, 그래프, 힙, 우선순위 큐가 있습니다.
1. 그래프



정점(Vertex)과 간선(Edge)으로 이루어진 그래프를 말합니다. 임의의 정점 A에서 다른 정점 B로 이동하는 경우를 예시로 들면 A, B라는
공간은 정점이 되고, A에서 B로 이동하는 경로를 간선이라고 칭합니다.
추가적으로 A에서 B로 갈 수 있는 간선만 주어진 경우에는 단방향 간선이 되고, A에서 B, B에서 A로 모두 갈 수 있는 경로가 주어진 경우는 양방향 간선이 됩니다.
가중치(Weight)는 정점 A에서 정점 B로 이동하는데 드는 비용으로 볼 수 있습니다. 이러한 그래프는 다양한 알고리즘에서 유용하게 쓰이는데, 대표적으로 다익스트라 알고리즘, 크루스칼 알고리즘 등이 있습니다.
2. 트리
트리는 그래프 중 하나로 그래프의 특징처럼 정점과 간선으로 이루어져 있고, 트리 구조로 배열된 일종의 계층적 데이터의 집합입니다. 루트노드, 내부 노드, 리프 노드 등으로 구성됩니다.

트리의 특징
- 부모, 자식 계층 구조를 가집니다. 5번 노드는 3번 노드의 자식이자 6번 노드의 부모이고, 1번 노드는 2번과 3번 노드의 부모가 됩니다.
- V - 1 = E의 공식을 가집니다. 그림의 트리 구조에서 정점은 10개이고, 간선은 9개이므로 직관적으로 파악할 수 있습니다.
- 임의의 두 노드 사이의 경로(간선)는 하나만 존재합니다. 즉, 트리 내의 간선은 반드시 존재한다는 것입니다.
트리의 구성
- 루트 노드 : 가장 상위에 있는 노드, 트리 문제에서 루트 노드를 중심으로 탐색하면 문제를 수월하게 풀 수 있게 됩니다.
- 내부 노드 : 루트 노드와 내부 노드 사이에 있는 노드를 의미합니다.
- 리프 노드 : 자식 노드가 없는 노드를 의미합니다.
트리의 높이와 레벨

- 깊이 : 루트 노드로부터 특정 노드까지 최단 거리로 갔을 때의 거리
- 높이 : 루트 노드로부터 리프 노드까지 거리가 가장 긴 거리를 의미
- 레벨 : 깊이와 같은 의미, 1번이 0 레벨이라고 가정하면, 리프 노드에 가까울수록 깊이가 커집니다.
- 서브트리 : 트리 내의 하위 집합인 서브트리, 5, 6, 7번 노드가 하나의 트리를 이루기에 이를 서브트리라고 부릅니다.
이진 트리
자식의 노드 수가 두 개 이하인 트리

- 정이진 트리(full binary tree) : 자식 노드의 수가 0개, 2개인 이진 트리
- 완전 이진 트리(complete binary tree) : 왼쪽에서부터 채워져 있는 이진 트리, 마지막 레벨을 제외하고는 모든 레벨이 완전히 채워져 있으며, 마지막 레벨의 경우 왼쪽에서 채워져 있습니다.
- 변질 이진 트리(degenerate binary tree) : 자식 노드가 하나밖에 없는 이진 트리
- 포화 이진 트리(perfect binary tree) : 모든 노드가 꽉 차 있는 이진 트리
- 균형 이진 트리 : 왼쪽과 오른쪽의 노드의 높이 차가 1이하인 이진 트리
이진 탐색 트리
이진 탐색 트리(Binary Search Tree)는 노드의 오른쪽 하위 트리에는 루트 노드 값 보다 큰 값이 저장되어 있고, 왼쪽 하위 트리에는 루트 노드 값보다 작은 값이 저장되어 있는 트리
삽입 순서가 선형적인 경우에는 탐색 연산에서 최악이지만, 그림과 같이 비선형적인 경우에는 평균적인 시간 복잡도를 지닙니다.
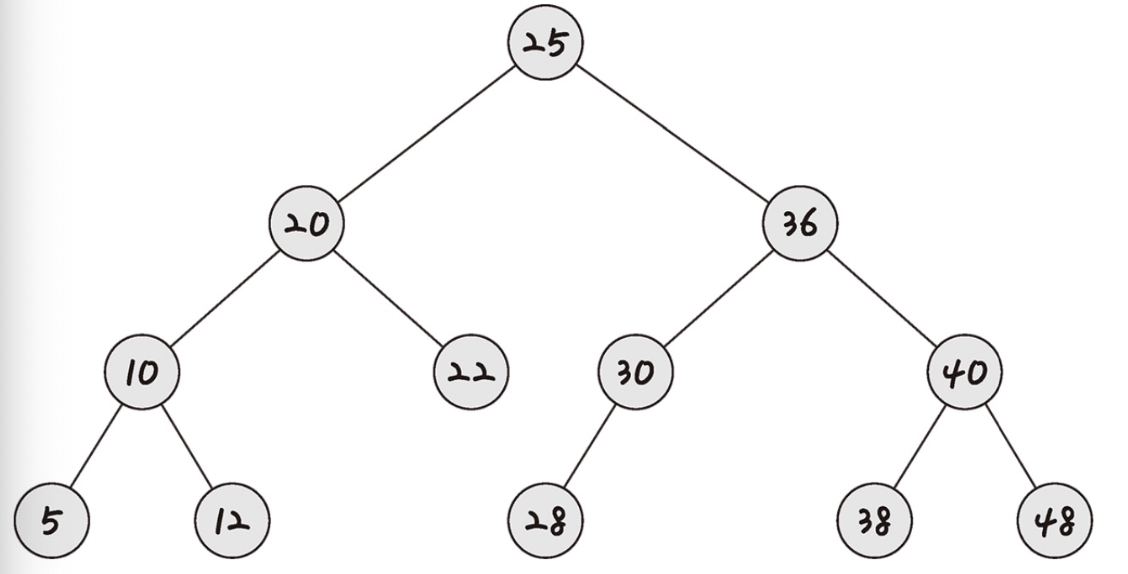
AVL 트리
AVL 트리는 앞서 설명한 최악의 경우 선형적인 트리가 되는 것을 방지하고, 스스로 균형을 잡는 이진 탐색 트리입니다. 두 자식 서브트리의 높이는 항상 최대 1만큼 차이가 나는 특징을 지닙니다.
레드 블랙 트리
균형 이진 탐색 트리로서 탐색, 삽입, 삭제 연산의 시간 복잡도가 O(logN)입니다. 각 노드는 빨간색 또는 검은색을 나타내는 비트를 저장하고, 삽입 및 삭제 중에 트리가 균형을 유지하도록 하는 데 사용됩니다. 예시로는 C++ STL의 set, map 등이 있습니다.

힙
힙은 완전 이진트리 기반의 자료 구조이며, 최소 힙, 최대 힙 두 가지가 있습니다.

- 최대힙 : 루트 노드에 있는 키는 모든 자식에 있는 키 중에서 가장 커야 하고, 각 노드의 자식 노드와의 관계에서도 동일하게 적용
- 최소힙 : 최대힙과 반대로 적용
최대힙의 삽입 및 삭제 연산

삽입 : 힙의 가장 마지막 노드에 삽입 후 부모 노드와의 값 비교를 통해 부모 노드가 값이 더 작으면 값을 스왑 해줍니다.
삭제 : 루트 노드가 삭제되고, 마지막 노드와 루트 노드를 스왑하고, 다양한 노드들과 스왑 과정을 거쳐 재구성
우선순위 큐
우선순위 대기열이라고도 부르며, 대기열에서 우선순위가 높은 요소가 낮은 요소보다 먼저 제공되는 자료 구조(default : 내림차순, 오름차순 설정 가능)
맵
맵(map)은 특정 순서에 따라 키와 매핑된 값의 조합으로 형성된 자료 구조입니다. 예시를 들어 "김태수" : "돼지", "김승범" : "돼지2"와 같이 특정 Key에 따른 Value값을 저장하고 싶은 경우에 사용합니다. Key, Value에 따른 자료형은 자유롭게 정할 수 있습니다. 삽입을 하게 되면 자동 정렬됩니다. 또한 Key, Value 값을 각각 first, second로 개별적으로 참조할 수 있습니다.
map은 정렬을 보장해 주지만, unordered_map은 정렬은 보장해주지 않습니다.
셋
셋(set)은 특정 순서에 따라 고유한 요소를 저장하는 컨테이너이면서, 중복되는 요소는 없고 특정 값만 저장하는 자료구조입니다.
해시 테이블
위에 설명한 많은 데이터들은 적은 개수의 해시 값으로 매핑한 테이블이며, 삽입, 삭제, 탐색 시 시간복잡도가 O(1)이고, unordered_map으로 구현할 수 있습니다.
오늘은 프로그래머가 코드를 설계할 때 고려해야 할 중요한 사항인 복잡도의 개념과 값을 일렬로 나열했는지의 여부에 따른 선형, 비선형 자료구조에 대해 간략하게 알아보았습니다.
참고 도서
면접을 위한 CS 전공지식 노트 : 네이버 도서
네이버 도서 상세정보를 제공합니다.
search.shopping.naver.com
'CS' 카테고리의 다른 글
| [컴퓨터 구조] chapter3 정리(컴퓨터 연산 : 부동소수점) (0) | 2023.05.28 |
|---|---|
| [컴퓨터 구조] chapter3 정리 (컴퓨터 연산 : 덧셈, 뺄셈, 곱셈, 나눗셈) (0) | 2023.05.22 |
| [컴퓨터 구조] chapter2-3 정리 (동기화, 컴파일러, 어셈블러, 링커, 로더) (3) | 2023.05.04 |
| [컴퓨터 구조] chapter2-2 정리(컴퓨터 언어 : 명령어) (2) | 2023.04.20 |
| [CS] 객체지향 생활체조 9가지 원칙 (0) | 2023.04.15 |