개요
Java에서는 방대한 데이터를 효율적으로 다루기 위해 Collection과 Stream이라는 강력한 도구를 제공합니다. Collection은 데이터를 저장하고 관리하기 위한 자료구조의 집합이며, Stream은 이러한 데이터를 보다 선언적이고 간결하게 처리할 수 있도록 돕는 API입니다. 이 두 가지를 이해하면 반복문과 조건문에 의존하던 기존 방식에서 벗어나, 가독성과 유지보수성이 높은 코드를 작성할 수 있게 됩니다.
이해를 돕기 위해 Stream, Collection 관련 예제 코드를 작성해 보았는데, 첨부된 링크를 통해 확인하실 수 있습니다.
https://github.com/daily1313/java-stream-collection
GitHub - daily1313/java-stream-collection: java stream and collection (java 17)
java stream and collection (java 17). Contribute to daily1313/java-stream-collection development by creating an account on GitHub.
github.com
Stream
- 일련의 데이터의 흐름을 표준화된 방법으로 쉽게 가공, 처리할 수 있도록 도와주는 클래스
- 요소들의 Stream에 함수형 연산을 지원하는 클래스
- Stream API는 이러한 작업을 간편하게 수행할 수 있도록 다양한 기능을 제공할 뿐만 아니라, 병렬 처리를 통해 처리 속도를 높일 수 있습니다.
- 따라서, Collection F/W를 통해 관리하는 데이터를 처리하기 위해 주로 사용합니다.
- Stream API의 다양한 기능들은 대부분 람다를 필요로 하기 때문에 람다를 이해하고 사용할 수 있어야 합니다.
Stream 연산

- 각 연산의 연결을 통해 파이프라인을 구성합니다.
- 파이프라인을 구성할 수 있다는 것은 스트림 대상 데이터에 대한 다양한 연산을 조합할 수 있다는 것을 의미합니다.
- 스트림을 이용한 연산 처리는 스트림 객체의 생성부터 중간 연산, 그리고 최종 연산 단계로 구분합니다.
- 스트림 객체가 제공하는 다양한 연산을 이해하고 연산에 필요한 람다표현식을 이해하고 적용하는 것이 중요합니다.
즉, 스트림 생성 -> 가공(중간 연산) -> 최종연산의 과정을 거치게 되는데, 해당 과정에 대해 상세하게 설명드리고 관련 예제도 살펴보도록 하겠습니다.
Stream 생성
- 데이터의 컬렉션(집합)을 Stream으로 변환하는 과정입니다.
- Stream API를 사용하기 위해서 최초 1번 수행되어야 하며, 생성 단계에서는 모든 데이터를 한꺼번에 불러오지 않고 필요할 때만 불러옵니다.
- 이를 통해 메모리 사용량을 최적화하고 효율성이 증대됩니다.
Stream 가공(중간 연산)
- 가공(중간연산): 소스의 데이터 집합을 원하는 형태로 가공하는 것
- filter, map과 같은 연산으로 Stream을 반환합니다.
- 중간 연산은 연속에서 호출하는 메소드 체이닝으로 구현이 가능합니다.
- 최종 연산이 실행되어야 중간연산이 처리되므로 중간연산들로만 구성된 메서드 체인은 실행되지 않습니다. (Lazy Evaluation)
- Lazy Evaluation: 최종 연산을 호출하기 전까지 중간 연산을 지연시키는 행위
- 가공의 종류
- filter: 필터 처리 (조건문을 통한 데이터 선별)
- map: 데이터 변환
- sorted: 정렬
- peek: 가공된 데이터를 파악하기 위한 용도
- disctinct: 중복 제거
- limit: 개수 제한
Stream 최종 연산
- 최종연산: Stream에 대한 최종 연산을 수행하는 것. (최종적인 목적물을 얻는 처리과정)
- forEach, collect와 같은 연산으로 void를 반환하거나 컬렉션 타입을 반환
- 스트림이 관리하는 전체 데이터에 대한 순회 작업은 최종 연산인 forEach() 메서드를 이용합니다.
- collect() 메소드는 스트림 처리 이후 처리된 데이터에 대해 Collection 객체로 반환하는 메서드입니다.
- 스트림의 최종 연산은 forEach()와 같은 스트림 처리 결과를 바로 확인할 수 있는 연산이 있고, 데이터를 모두 소모한 이후에 그 결과를 알 수 있는 count()와 같은 연산이 있습니다.
- 이 외에도 특정 데이터를 검색할 수 있는 allMatch(), anyMatch() 등과 같은 다양한 메서드들을 제공합니다.
- 최종 연산 종류
- forEach(): stream의 각 요소를 순회하면서 출력 등의 처리를 위해 사용합니다.
- reduce(): stream의 요소를 줄여나가면서 연산을 수행합니다.
- findFirst(), findAny(): 특정 조건에 맞는 요소를 찾기 위해 사용합니다.
- anyMatch(), allMatch(), noneMatch(): 조건에 맞는지 확인을 위해 사용합니다.
- count(), min(), max(), sum(), average(): 요소의 개수, 최소(대)값, 합계, 평균을 위해 사용합니다.
- collect(): stream의 요소를 수집하여 원하는 형태로 변환하기 위해서 사용합니다.
- toList(), toSet(), toCollection(), toArray(), toMap()
Stream 특징
- 선언적으로 코딩이 가능합니다.
- 연속적으로 필터링, 매핑, 정렬을 체이닝으로 표현할 수 있습니다.
- 간결하고 명확한 코드로 데이터를 처리할 수 있어서 코드의 유지보수성과 가독성이 향상됩니다.
- 병렬처리를 지원합니다. (멀티스레드로 병렬처리 후 대량의 데이터를 빠르고 쉽게 처리) (parallel(), parallelStream())
Stream의 전 과정에 대해 상세하게 설명드렸으니, Stream을 활용한 예제 코드를 살펴보겠습니다.
Stream Example
classpath에 user.csv 파일이 제공되어 있다고 가정합니다.
이름, 취미, 소개
김프로, 축구:농구:야구, 구기종목 좋아요
정프로, 개발:당구:축구, 개발하는데 뛰긴 싫어
앙몬드, 피아노, 죠르디가 좋아요 좋아좋아너무좋아
죠르디, 스포츠댄스:개발, 개발하는 죠르디 좋아
박프로, 골프:야구, 운동이 좋아요
정프로, 개발:축구:농구, 개발도 좋고 운동도 좋아
1. 취미별 선호 인원 구하기
- Solution-1
public Map<String, Integer> quiz1() throws IOException {
List<String[]> csvLines = readCsvLines();
Map<String, Integer> results = csvLines.stream() // 스트림 생성
.flatMap(line -> Arrays.stream(line[1].replaceAll("\\s", "").split(":"))) // 중간 연산
.collect(Collectors.toMap(k -> k, v -> 1, Integer::sum)); // 최종 연산
results.entrySet().forEach(entry -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
return results;
}
- Solution-2
public Map<String, Integer> quiz1() throws IOException {
List<String[]> csvLines = readCsvLines();
Map<String, Integer> results = new HashMap<>();
csvLines.stream()
.flatMap(line -> Arrays.stream(line[1].replaceAll("\\s", "").split(":")))
.forEach(hobby -> results.merge(hobby, 1, Integer::sum));
results.entrySet().forEach(entry -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
return results;
}
private List<String[]> readCsvLines() throws IOException {
CSVReader csvReader = new CSVReader(new FileReader(getClass().getResource("/user.csv").getFile()));
csvReader.readNext();
return csvReader.readAll();
}- csv 파일을 CsvReaders 클래스를 통해 한 줄씩 파싱합니다.
- flatMap 메서드를 통해 콜론을 기반으로 파싱 한 데이터를 한 번에 불러옵니다.
- flatMap: Stream<String> 형식으로 모든 원소가 한 줄로 펼쳐집니다. --> flatMap을 활용하려면 새롭게 스트림을 생성 (Arrays.stream())을 해주어야 합니다.
- Map: Stream<Stream<String>> 형식으로 스트림 안에 스트림이 들어있는 형태입니다.
- collect(), forEach() 메서드를 통해 각 취미별 선호하는 count를 집계합니다.
2. List 데이터 가공하기
private static List<String> WORDS = Arrays.asList("TONY", "a", "hULK", "B", "america", "X", "nebula", "Korea");
// 2.1 List에 저장된 단어들의 접두사가 각각 몇개씩 있는지 Map<String, Integer>으로 변환하여라.
// ex) ("T", 1), ("a", 2) ...
public Map<String, Integer> quiz1() {
Map<String, Integer> results = WORDS.stream()
.map(word -> word.substring(0, 1))
.collect(Collectors.toMap(key -> key, value -> 1, Integer::sum));
results.entrySet().forEach(entry -> {
System.out.println(entry.getKey() + " : " + entry.getValue());
});
return results;
}
// 2.2 List에 저장된 단어들 중에서 단어의 길이가 2 이상인 경우에만, 모든 단어를 대문자로 변환하여 스페이스로 구분한 하나의 문자열로 합한 결과를 반환하여라.
// ex) ["Hello", "a", "Island", "b"] -> “H I”
public String quiz2() {
String result = WORDS.stream()
.filter(word -> word.length() >= 2)
.map(word -> word.substring(0, 1).toUpperCase())
.collect(Collectors.joining(" "));
System.out.println(result);
return result;
}- 조건에 입각하여 filter 처리를 해줍니다. (Prefix 추출, 단어수 2 이상)
- map으로 Prefix 데이터를 변환해 줍니다.
- collect()를 통해 최종 연산의 결과를 테스트 케이스에 맞게 반환합니다.
3. 문자열 가공, 임의 로또 번호 생성, 주사위 값 6인 리스트 반환
public class Q5 {
private static final String[] STRING_ARR = {"aaa", "bb", "c", "dddd"};
// 5.1 모든 문자열의 길이를 더한 결과를 출력하여라.
public int quiz1() {
return Arrays.stream(STRING_ARR)
.mapToInt(String::length)
.sum();
}
// 5.2 문자열 중에서 가장 긴 것의 길이를 출력하시오.
public int quiz2() {
return Arrays.stream(STRING_ARR)
.mapToInt(String::length)
.max().orElse(0);
}
// 5.3 임의의 로또번호(1~45)를 정렬해서 출력하시오.
public List<Integer> quiz3() {
return IntStream.rangeClosed(1, 46)
.distinct()
.limit(6)
.sorted()
.boxed() // IntStream -> Stream<Integer>로 변환
.collect(Collectors.toList());
}
// 5.4 두 개의 주사위를 굴려서 나온 눈의 합이 6인 경우를 모두 출력하시오.
public List<Integer[]> quiz4() {
return IntStream.rangeClosed(1, 5)
.mapToObj(i -> new Integer[]{i, 6 - i})
.collect(Collectors.toList());
}
}
- 5-1, 5-2: 문자열 배열을 Int 형식으로 변환하여 문자열의 길이의 합, 최대 길이를 구해줍니다.
- IntStream을 활용하여 로또 번호를 생성합니다.
- distinct(): 중복을 제거
- limit(): 6개만 선택
- sorted(): 오름차순 정렬
- boxed(): IntStream -> Stream<Integer>로 변환
- IntStream을 활용하여 주사위의 눈의 합이 될 수 있는 수를 생성해 줍니다. (1~5)
- mapToObj(): 각 i에 대해 주사위의 눈이 합이 6이 되는 (i, 6-i) 쌍을 Integer[]로 생성합니다.
- 이후 List로 수집합니다.
Collection

Java Collection Framework (JCF)
- 데이터를 crud 하는데 필요한 자료구조와 알고리즘을 표준화해서 제공해 주는 클래스, 인터페이스의 집합
- Collection 인터페이스
- List, Set, Queue 인터페이스의 구현체가 존재합니다.
- Map 인터페이스
- Collection과는 별개로 Map 인터페이스의 구현체가 존재합니다.
Iterable Interface
- 컬렉션 인터페이스들의 가장 최상의 인터페이스
- 컬렉션들을 배우다 보면 자료들을 순회할 때 이터레이터 객체를 다뤄보게 되는데, 이터레이터 객체를 관리하는 인터페이스
| 메서드 | 설명 |
| default void forEach(Consumer<? super T> action) | 함수형 프로그래밍 전용 루프 메서드 |
| Iterator<T> iterator() | 컬렉션에서 이터레이터 구현 |
| default Spliterator<T> splierator() | 파이프라이닝 관련 메서드 |
Collection Interface

- List, Set, Queue를 상속하는 상위 컬렉션 타입
- 업캐스팅으로 다양한 종류의 컬렉션 자료형을 받아 자료를 crud할 수 있습니다.
| 메서드 | 설명 |
| boolean add(Object o) boolean addAll(Collection c) |
Collection에 객체 추가 |
| boolean contains(Object o) boolean containsAll(Collection c) |
Collection에 객체들이 포함되어있는지 check |
| boolean remove(Object o) boolean removeAll(Collction c) |
Collection에서 객체 삭제 |
| boolean retainAll(Collection c) | Collection에 지정한 객체를 제외한 모든 객체 삭제 |
| void clear() | Collection의 모든 객체를 삭제 |
| boolean equals(Object o) | 동일한 Collection인지 비교 |
| int hashCode() | Collection의 hash code를 반환 |
| boolean isEmpty() | Collection이 비어있는지 확인 |
| Iterator iterator() | Collection의 iterator를 얻어서 반환 |
| int size() | Collection에 저장된 객체의 개수를 반환 |
List (ArrayList, LinkedList, Vector, Stack)
ArrayList (조회 성능 우수)
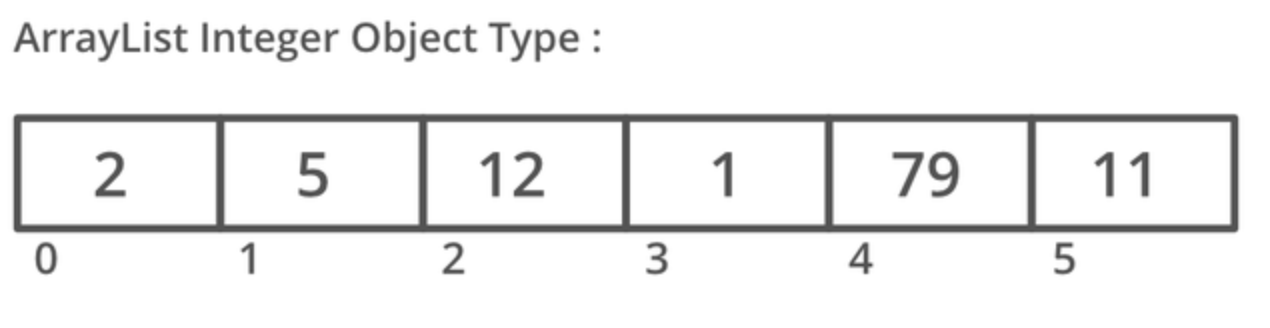
- 배열을 이용하여 만든 리스트입니다.
- 데이터의 저장순서가 유지되고 중복을 허용합니다.
- 데이터량에 따라 공간(capacity)을 자동으로 설정합니다. (Array와의 큰 차이점)
- 단방향 포인터 구조로 자료에 대한 순차적인 접근에 강점이 있어 조회가 빠릅니다. (삽입/삭제는 성능이 떨어집니다.)
LinkedList (삽입/삭제 성능 우수)
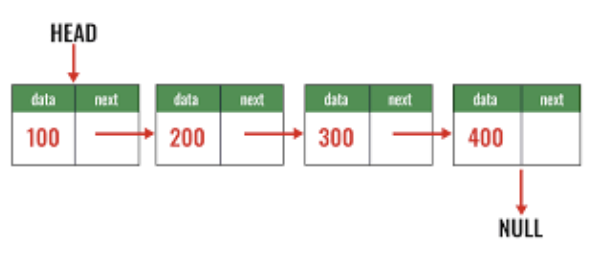
- 노드를 연결하여 리스트처럼 만든 컬렉션 (배열 X)
- 데이터의 중간 삽입, 삭제가 빈번할 경우 빠른 성능을 보장합니다.
- 임의 요소에 대한 조회 성능이 좋지 않습니다.
- 자바의 LinkedList는 양방향 포인터 구조로 이루어집니다.
- LinkedList는 리스트 용도 이외에도 스택, 큐, 트리 등의 자료구조의 근간이 됩니다.
Vector (동기화 보장)
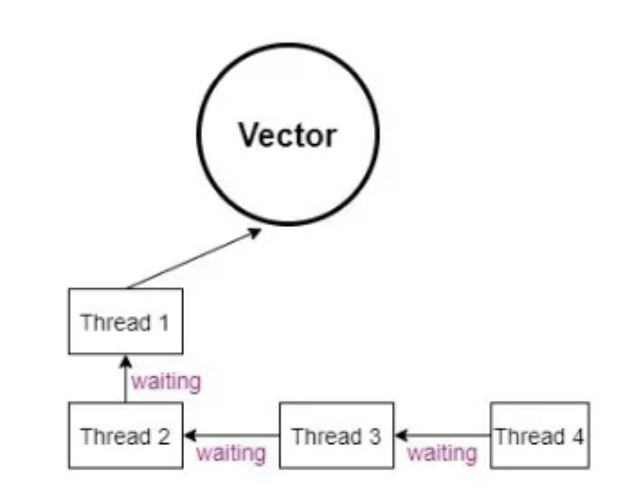
- ArrayList의 구형 버전으로서 모든 메서드가 동기화(synchronized) 되어 있어 Thread-safe 합니다.
- 구버전 자바와의 호환성을 가집니다.
- 내부에서 자동으로 동기화가 일어나, 성능이 좋지 않으며 무거워서 잘 사용하지 않습니다.
- 컬렉션에 동기화가 필요하면, Collections.synchronizedList() 메서드를 이용해 ArrayList를 동기화 처리 합니다.
Stack
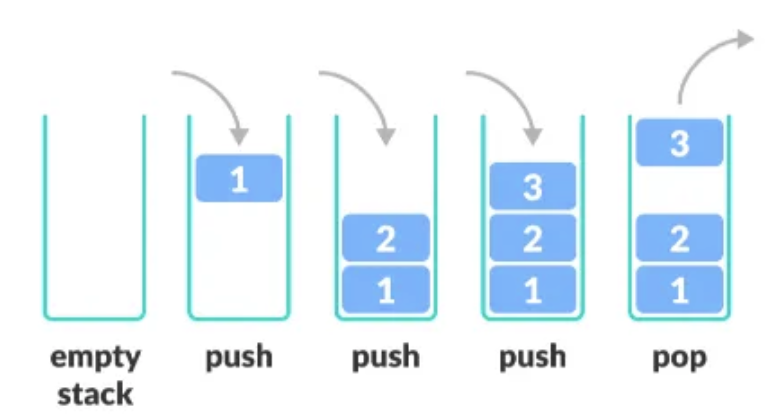
- LIFO(Last-In-First-out) 구조의 자료구조
- 마지막에 들어온 원소가 처음으로 나갑니다.
- 들어올 때는 push, 나갈 때는 pop을 사용합니다.
- Stack은 Vector를 상속하기 때문에 문제점이 많아 잘 안 쓰입니다. (ArrayDeque로 대체)
Set (HashSet, LinkedHashSet, TreeSet)

- 데이터의 중복을 허용하지 않고 순서를 유지하지 않는 데이터의 집합 리스트
- 순서 자체가 없으므로 인덱스로 객체를 검색해서 가져오는 get(index) 메서드도 존재하지 않습니다.
- 중복 저장이 불가능하기에 심지어 null도 하나만 저장할 수 있습니다.
Set Method
| 메서드 | 설명 |
| boolean add(E e) | 주어진 객체를 저장 후 true, false 리턴 |
| boolean contains(Object o) | 주어진 객체가 저장되었는지의 여부를 리턴 |
| Iterator<E> iterator() | 저장된 객체를 한번씩 가져오는 반복자를 리턴 |
| isEmpty() | 컬렉션이 비었는지 여부를 검사 |
| int Size() | 저장되어 있는 전체 객체 수를 리턴 |
| void clear() | 저장된 모든 객체를 삭제 |
| boolean remove(Object o) | 주어진 객체를 삭제 |
HashSet
- 배열과 연결노드를 결합한 자료구조 형태
- 가장 빠른 임의 검색 접근 속도를 보장합니다.
- 추가, 삭제, 검색, 접근성이 모두 뛰어납니다.
- 대신 순서를 전혀 예측할 수 없습니다.
LinkedHashSet
- 순서를 가지는 Set 자료구조
- 추가된 순서 또는 가장 최근에 접근한 순서대로 접근 가능
- 만일 중복을 제거하는 동시에 저장한 순서를 유지하고 싶다면, HashSet 대신 LinkedHashSet을 사용하면 됩니다.
TreeSet
- 이진 검색 트리 (binary search tree) 자료구조 형태로 데이터 저장
- 중복을 허용하지 않고, 순서를 가지지 않습니다.
- 대신 데이터를 정렬하여 저장하고 있다는 특징이 있습니다.
- 정렬, 검색, 범위 검색에 높은 성능을 가집니다.
Map (HashMap, LinkedHashMap, TreeMap, HashTable)
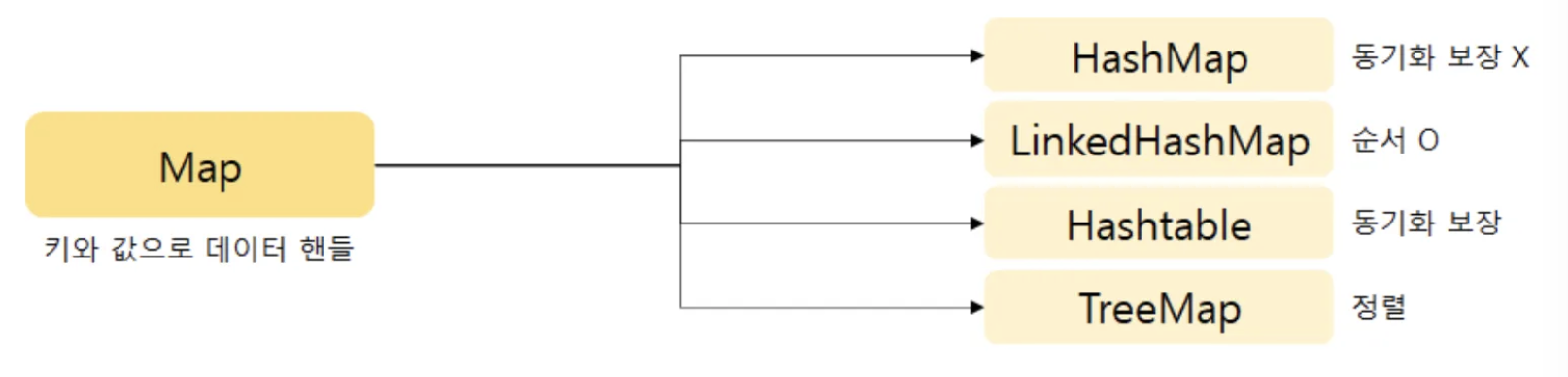
- key와 value 쌍으로 연관 지어 이루어진 데이터의 집합
- value는 중복해서 저장될 수 있지만, key는 고유한 값이어야 합니다.
- 기존에 데이터와 중복된 키와 값을 저장하면 기존의 값은 없어지고, 마지막에 저장된 값만 남게 됩니다.
- 저장 순서가 유지되지 않습니다.
Map Method
| 메서드 | 설명 |
| void clear() | Map의 모든 객체를 삭제 |
| boolean containsKey() | 지정된 key 객체와 일치하는 객체가 있는지 확인 |
| boolean containsValue() | 지정된 value 객체와 일치하는 객체가 있는지 확인 |
| Set entySet() | Map에 저장된 key-value 쌍을 Map.Entry 타입의 객체로 저장한 Set을 반환 |
| boolean equals() | 동일한 Map인지를 비교 |
| Object get() | 지정한 key 객체에 대응하는 value 객체를 반환 |
| int hashCode() | 해시 코드를 반환 |
| boolean isEmpty() | Map이 비어있는지 확인 |
| Set keySet() | Map에 저장된 모든 key 객체를 반환 |
| Object put() | Map에 저장된 key 객체와 value 객체를 연결하여 저장 |
| putAll(Map t) | 지정된 key 객체와 일치하는 key-value 쌍을 추가 |
| remove() | 지정된 key 객체와 일치하는 key-value 객체를 삭제 |
| int size() | Map에 저장된 key-value 쌍의 개수를 반환 |
Map.Entry 인터페이스
- Map.Entry 인터페이스는 Map 인터페이스 안에 있는 내부 인터페이스입니다.
- Map에 저장되는 key-value 쌍의 Node 내부 클래스가 이를 구현하고 있습니다.
HashMap<String, Integer> map = new HashMap<>();
map.put("A", 0);
map.put("B", 0);
map.put("C", 0);
Set<Map.Entry<String, Integer>> entry = map.entrySet();
System.out.println(entry);
for (Map.Entry<String, Integer> e : entry) {
System.out.println(e.getKey() + " = " + e.getValue());
}
HashMap
- HashTable을 보완한 컬렉션
- 배열과 연결이 결합된 Hashing 형태로, key, value를 묶어 하나의 데이터로 저장합니다.
- 중복을 허용하지 않고 순서를 보장하지 않습니다.
- key, value 값으로 null을 허용합니다.
- 추가, 삭제, 검색, 접근성이 모두 뛰어납니다.
- 동기화되지 않아 멀티쓰레드 환경에서는 안전하지 않습니다.
LinkedHashMap (순서 보장)
- HashMap을 상속하고, Entry들이 연결 리스트를 구성하여 데이터의 순서를 보장합니다.
- 일반적인 Map 자료구조는 순서를 가지지 않지만, LinkedHashMap은 들어온 순서대로 순서를 가집니다.
TreeMap (정렬 O)
- 이진 검색 트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장합니다. (TreeSet과 동일한 원리)
- TreeMap은 SortedMap 인터페이스의 구현체로서, Key값을 기준으로 정렬되는 특징을 가지고 있습니다.
- 정렬된 순서로 key/value 값을 저장하므로 조회 성능이 뛰어나지만, 저장과 동시에 정렬 과정이 일어나므로 저장 시간이 오래 걸립니다.
HashTable
- 자바 초기 버전에 나온 클래스
- Key를 특정 해시 함수를 통해 해싱한 후 나온 결과를 배열의 인덱스로 사용하여 Value를 찾는 방식으로 동작됩니다.
- HashMap보다는 느리지만 동기화가 기본적으로 지원됩니다.
<참고 자료>
https://www.elancer.co.kr/blog/detail/255
java stream이란 특징부터 사용하는 이유까지 모두 알려드립니다. I 이랜서 블로그
데이터가 중요해 질수록 강력한 데이터 처리 기능을 선보이며 데이터 처리 효율을 높여주는 ‘Java Stream’를 찾는 사람들이 많아지고 있는데요. 이랜서에서 java stream이란 무엇인지 자세히 알려
www.elancer.co.kr
https://jeong-pro.tistory.com/212
개발자 기술 과제, 라이브 코딩 테스트 후기(자바 스트림 활용 능력 with flatMap)
과제 겸 라이브 코딩 1. 후기 제가 생각하는 일반적인 개발자 채용 프로세스는 아래와 같습니다. 서류전형 → 코딩테스트(온라인) → 기술면접 → 임원면접 → 최종합격 여기에 조금 추가되면 코
jeong-pro.tistory.com
🧱 Java Collections Framework 종류 💯 총정리
Java Collection Framework 자바 새내기분들은 컬렉션 프레임워크라는 단어에 뭔가 거창하고 어려운 느낌이 들수 있겠지만, 그냥 자료 구조(Data Structure) 종류의 형태들을 자바 클래스로 구현한 모음집
inpa.tistory.com
https://gangnam-americano.tistory.com/41
[JAVA] Java 컬렉션(Collection) 정리
[JAVA] Java 컬렉션(Collection) 정리 ■ Java Collections Framework(JCF) Java에서 컬렉션(Collection)이란 데이터의 집합, 그룹을 의미하며 JCF(Java Collections Framework)는 이러한 데이터, 자료구조인 컬렌션과 이를 구
gangnam-americano.tistory.com
'Backend' 카테고리의 다른 글
| [Java] final, interface, abstract class (1) | 2025.08.27 |
|---|---|
| [Java] Garbage Collection (1) | 2024.12.05 |
| [Java] ClassNotFoundException VS NoClassDefFoundError (1) | 2024.02.06 |
| [Java] Exception (0) | 2023.08.21 |